Tensor core 详解
Tensor Core剖析
在 NVIDIA 的通用 GPU 架构中,存在三种主要的核心类型:CUDA Core、Tensor Core 以及 RT Core。NVIDIA 显卡从 Tesla 架构开始,所有 GPU 都带有有 CUDA Core,但 Tensor Core 和 RT Core 确并非都具有。在 Fermi 架构之前,GPU 的处理核心一直被叫做 Processor core(SPs),随着 GPU 中处理核心的增加,直到 2010 年 NVIDIA 的 Fermi 架构它被换了一个新名字 CUDA Core。
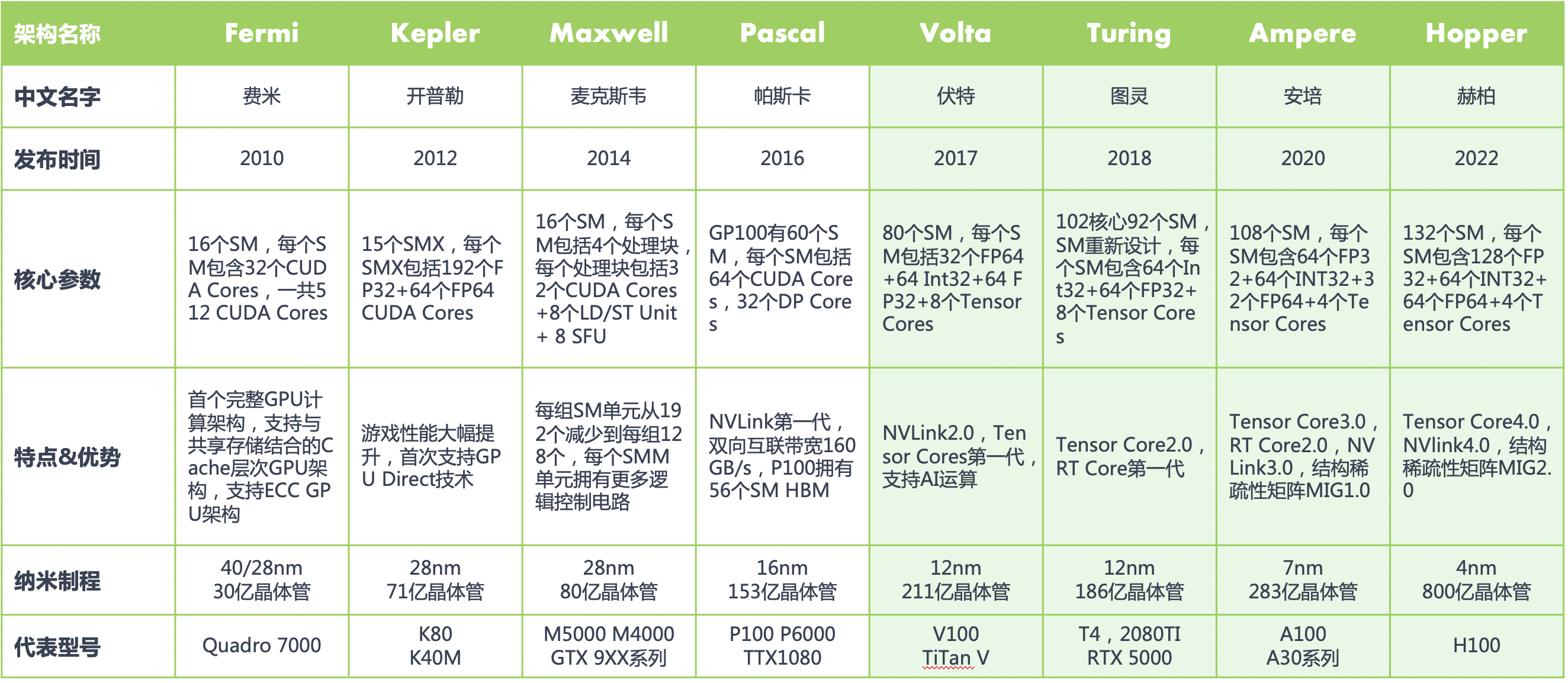
NVIDIA架构变迁图
CUDA Core在执行矩阵乘时把乘和加分开执行,把数据放到寄存器,执行乘操作,得到的结果再放到寄存器,执行加操作,再将得到的结果放到寄存器;

CUDA Core与Tensor Core
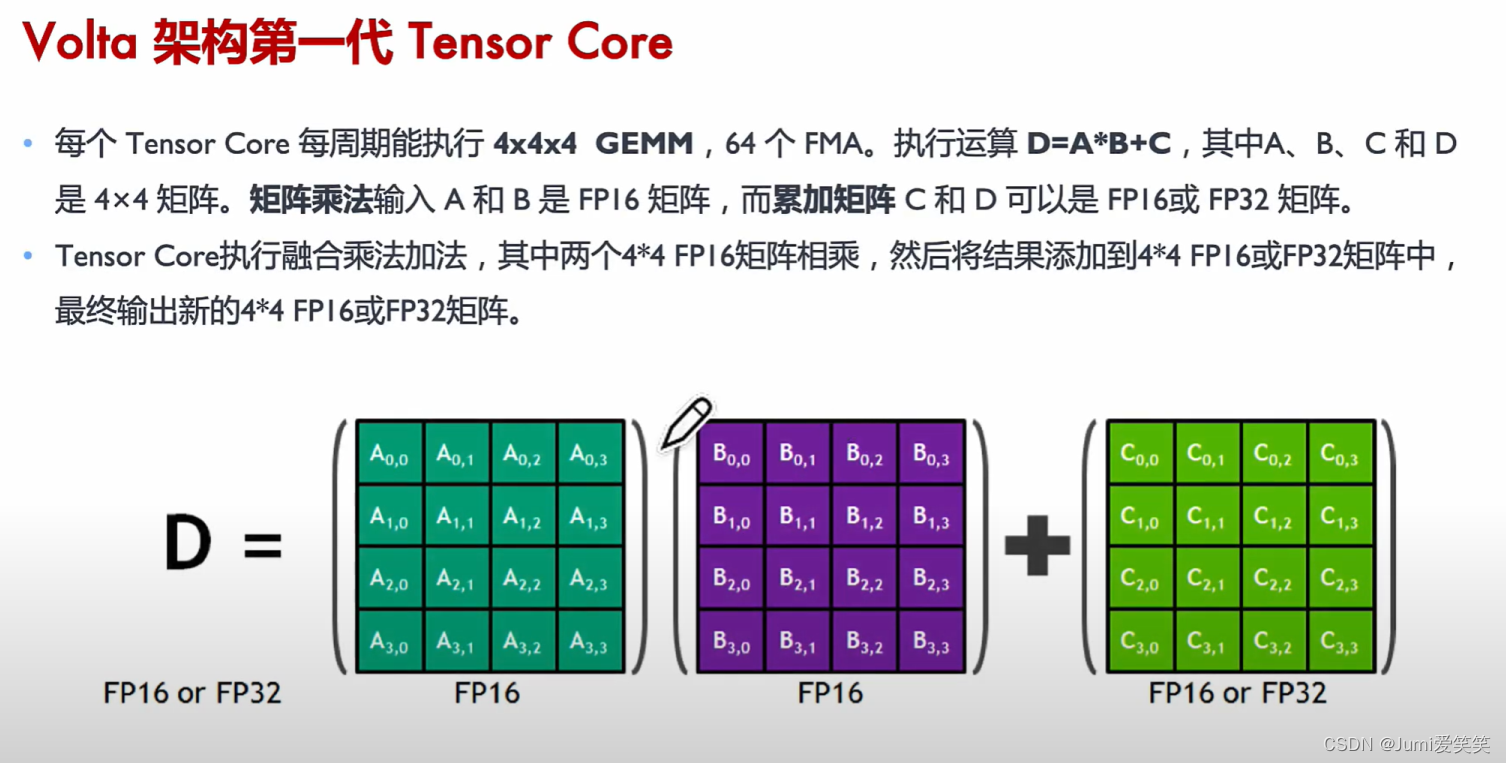
而Tensor Core 是 NVIDIA 推出的专门用于加速深度学习和高性能计算任务的硬件单元。它们最早在 NVIDIA 的 Volta 架构中引入,随后在 Turing 和 Ampere 架构中得到进一步改进和广泛应用。ensor Core 是针对深度学习和 AI 工作负载而设计的专用核心,可以实现混合精度计算并加速矩阵运算,尤其擅长处理半精度(FP16)和全精度(FP32)的矩阵乘法和累加操作。
Tensor Core
- 加速矩阵计算:
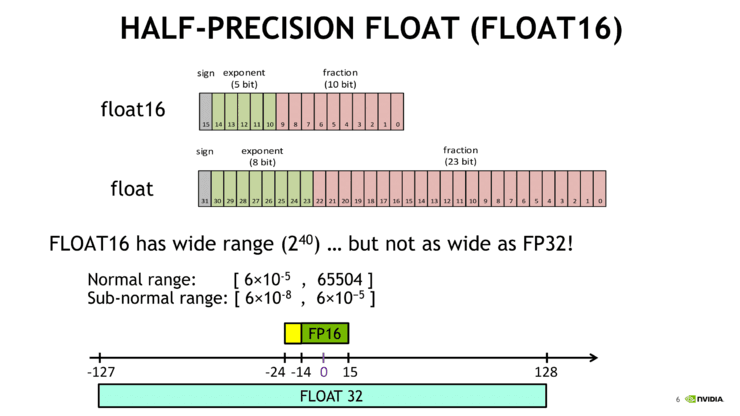
Tensor Core 主要用于加速矩阵乘法运算,这是深度学习中的基础操作。它们能够执行混合精度计算,其输入使用 FP16 精度,接着使用 FP16 进行计算,并使用 FP32 进行累加,从而大大提高计算效率和速度。
Tensor Core
- 优化深度学习模型训练和推理:
Tensor Core 可以显著缩短深度学习模型的训练时间。在推理阶段,它们可以加速模型的前向传播过程,提高实时应用的性能。
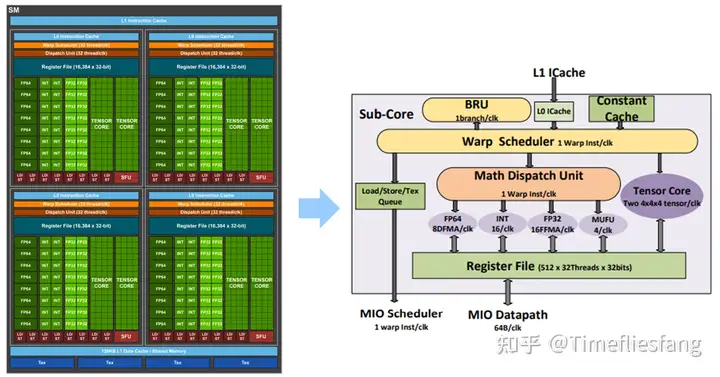
Volta架构
如上图所示,在NV的Volta架构中,一个SM中有4个Sub-core,而每个Sub-core里面除了执行标量运算的多个CUDA Core以外,还有两个Tensor Core,他们共享一套Register File,每个Sub-Core中有一个Warp Scheduler,即同一时刻每个Sub-Core的资源只能分配给1个线程束(Warp)。
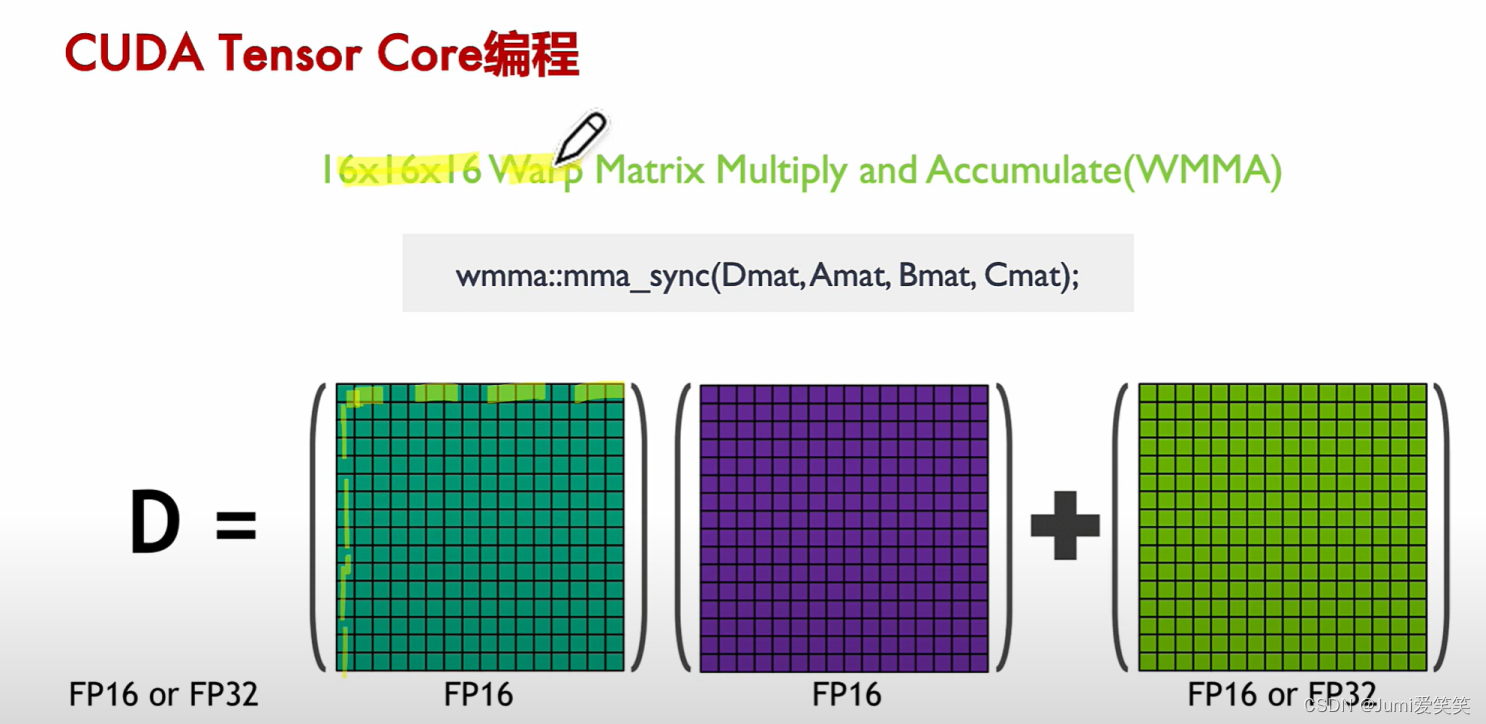
而在实际编程中,CUDA开放了WMMA的一系列API来使用户可以对tensor core进行编程,而且其中的矩阵乘法API wmma.mma.sync实际上每次接收的是1616矩阵乘加运算D = A * B + C,这好像与tensor core定义的每周期44矩阵乘不一致,实际上这里调用的mma API不是在一个周期内完成的,准确地说,这是给一个warp分配了16*16的矩阵乘的运算量,在若干个周期内完成。
Caution
TODO: (1)1616的矩阵乘法所需的数据A,B,C是如何分配给1个warp内的32个线程的?
(2)Tensor Core具体是按照什么顺序来分步执行完这个1616的矩阵乘法的,耗费了多少个周期?
https://zhuanlan.zhihu.com/p/660531822
https://arxiv.org/pdf/1811.08309
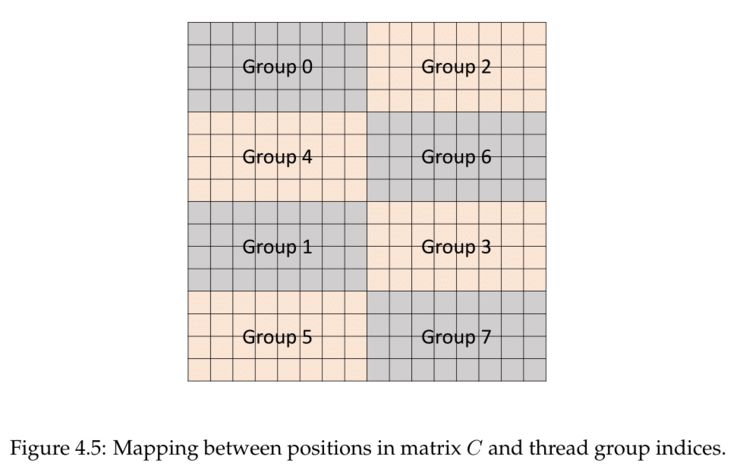
在CUDA程序中,CUDA将Tensor Core 硬件执行 4*4 的矩阵通过warp线程束打包为 16*16 的矩阵。

Tensor Core_CUDA
TC线程处理细节
从概念上讲,Tensor Core在4*4子矩阵上运行,以计算更大的16*16矩阵。warp线程被分成8组,每组4个线程,每个线程组连续计算一个8*4块,总共要经过4组的过程,每一个线程组都处理了目标矩阵的1/8。
CUDA在线程束层面的操作通过CUDA C++WMMA API接口实现,直接对于Tensorcore进行操作的话,颗粒度太小,所以把多个Tensorcore聚集起来放到一个wrap level的层面进行调度:
Tensor Core_编程
🌰:
// 包含 NVIDIA CUDA 的矩阵乘法和累加(WMMA)库,并使用 nvcuda 命名空间,以便访问 WMMA 接口。
#include <mma.h>
using namespace nvcuda;
// 核函数定义,用于执行矩阵乘法
__global__ void wmma_ker(half *a, half *b, float *c) {
// 声明片段,用于存储矩阵数据
wmma::fragment<wmma::matrix_a, 16, 16, 16, half, wmma::col_major> a_frag; // 矩阵A的片段,列主序
wmma::fragment<wmma::matrix_b, 16, 16, 16, half, wmma::row_major> b_frag; // 矩阵B的片段,行主序
wmma::fragment<wmma::accumulator, 16, 16, 16, float> c_frag; // 用于累加的片段
// 初始化输出片段c_frag为零
wmma::fill_fragment(c_frag, 0.0f);
// 加载输入矩阵数据到片段中
wmma::load_matrix_sync(a_frag, a, 16);
wmma::load_matrix_sync(b_frag, b, 16);
// 执行矩阵乘法
wmma::mma_sync(c_frag, a_frag, b_frag, c_frag);
// 将结果存储到输出矩阵中
wmma::store_matrix_sync(c, c_frag, 16, wmma::mem_row_major);
}Note
该程序通过数据片段化、混合精度计算、同步计算、高效存储和加载以及利用 Tensor Core 等多种优化手段来提高矩阵乘法运算的效率。矩阵被分解成小块(片段)存储在专用寄存器中,以减少内存访问延迟;输入矩阵 A 和 B 使用半精度(FP16)表示,累加结果使用单精度(FP32)表示,从而在保证计算精度的同时提高计算速度和效率;mma_sync 操作确保所有线程同步执行矩阵乘法并将结果累加到累加片段中,保证了计算的一致性和准确性;load_matrix_sync 和 store_matrix_sync 操作高效地加载和存储数据,最大限度地减少数据传输延迟;程序通过 WMMA 接口直接利用 NVIDIA GPU 中的 Tensor Core,这些专用硬件单元能够以极高的吞吐量执行矩阵运算,从而大幅提高深度学习和高性能计算任务的效率。
GEMM在Tensor Core上的加速实现:
GEMM(通用矩阵乘):GEMM通常指的矩阵乘法的优化,针对不同的硬件架构和计算需求,有多种优化的GEMM实现,如基于CPU的优化、基于GPU的优化(使用CUDA、OpenCL等编程模型),以及专用的张量处理单元(TPU、NPU)等。这些优化方法通常利用并行计算、向量化指令和数据局部性等技术,以提高矩阵乘法的计算性能。
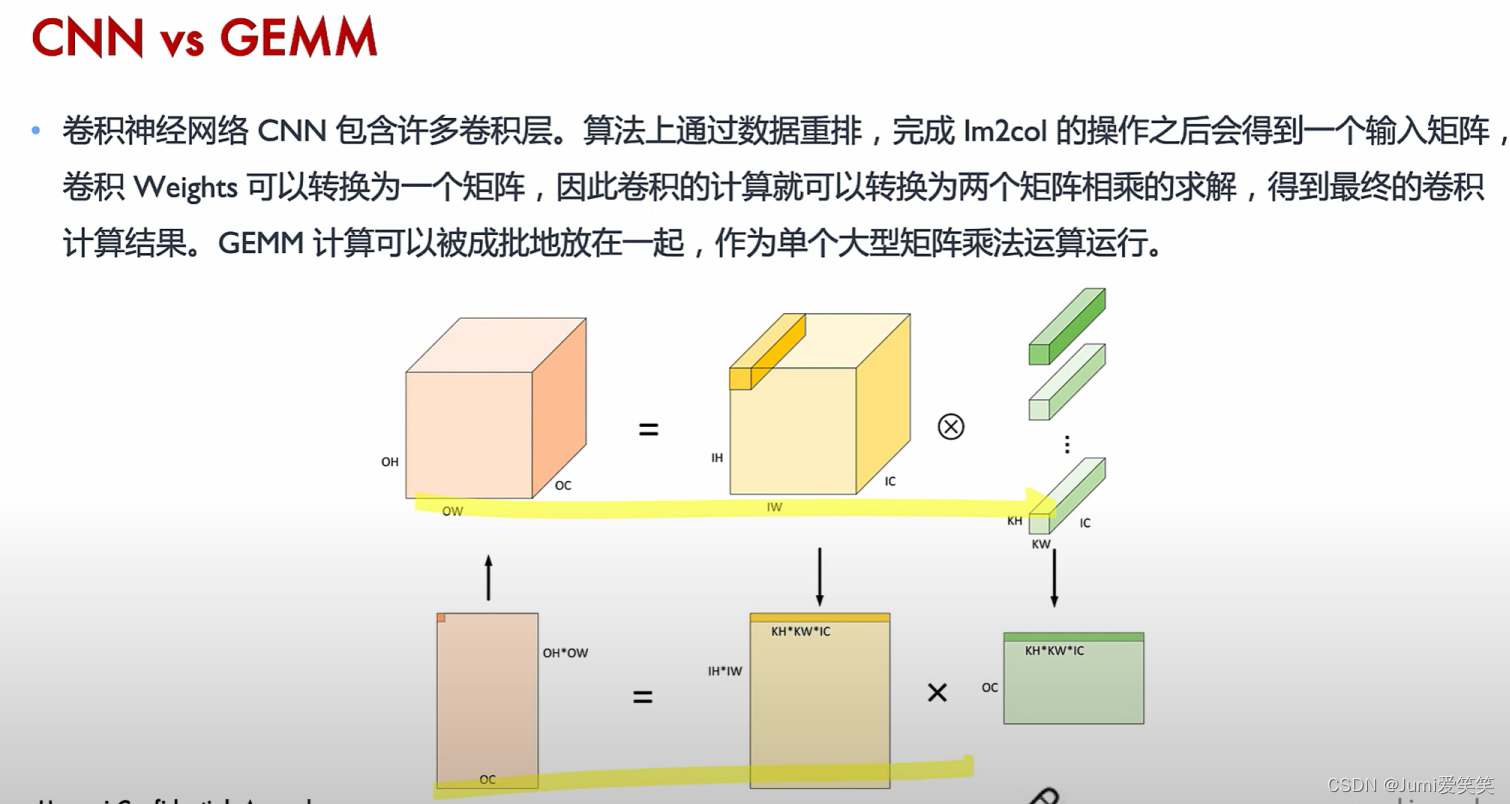
GEMM
如上图所示,可以将CNN卷积操作通过im2col展开感受野等一系列操作形成大型矩阵乘,从而使用GEMM进行优化加速。

GEMM CUDA
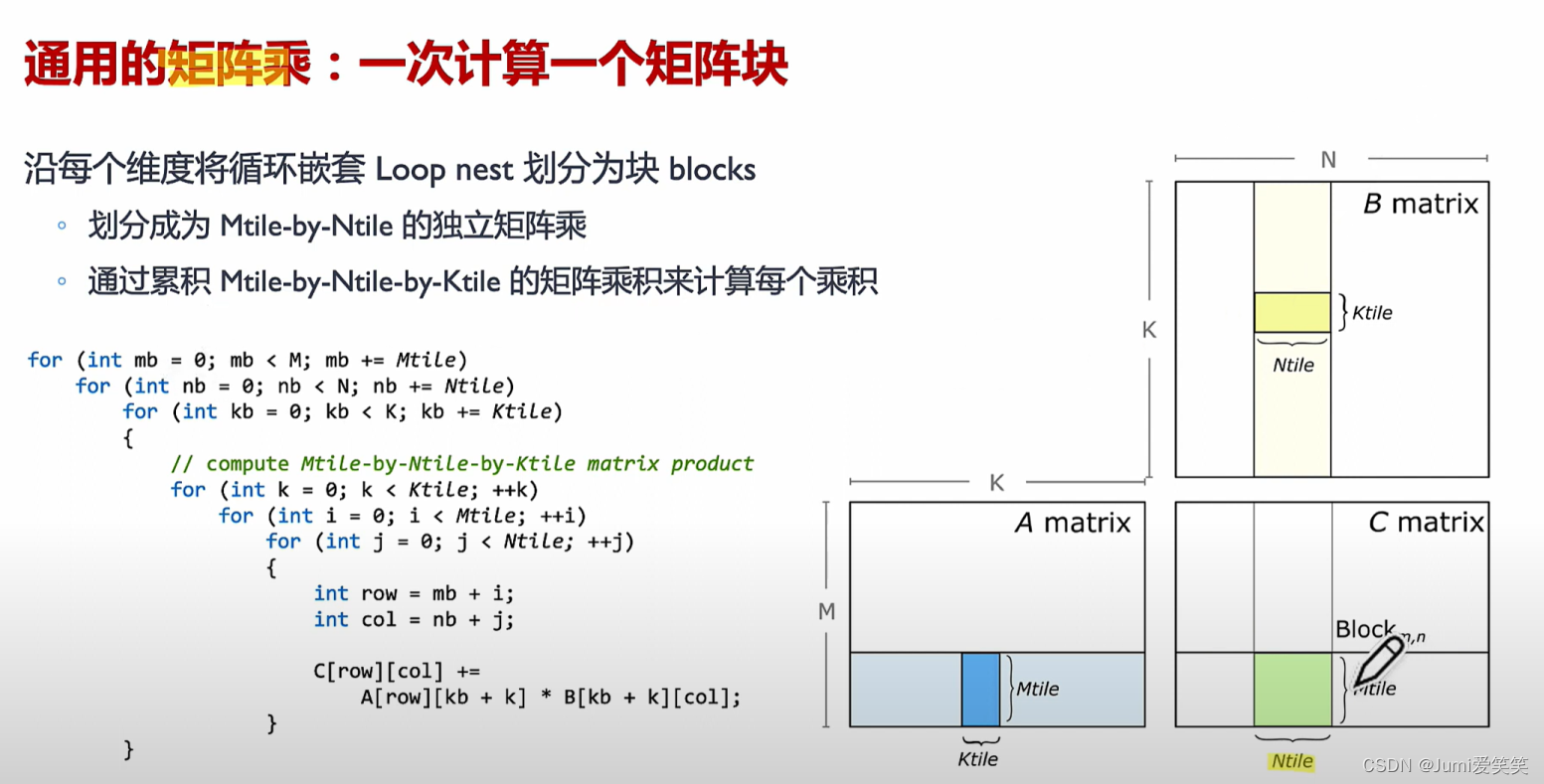
以下例子说明了GEMM矩阵相乘的具体执行过程,其会将大的矩阵块划分成一个个的fragment,每一个fragment的矩阵相乘对应一个thread block,每一个thread block又可以划分成多个wrap,每一个wrap下面可以执行多个thread,每一个thread里面循环执行Tensor core 4*4的矩阵操作:
通用矩阵乘
首先通用的矩阵乘是将A B矩阵对应位置fragment矩阵进行相乘,通过两层矩阵素质乘实现。
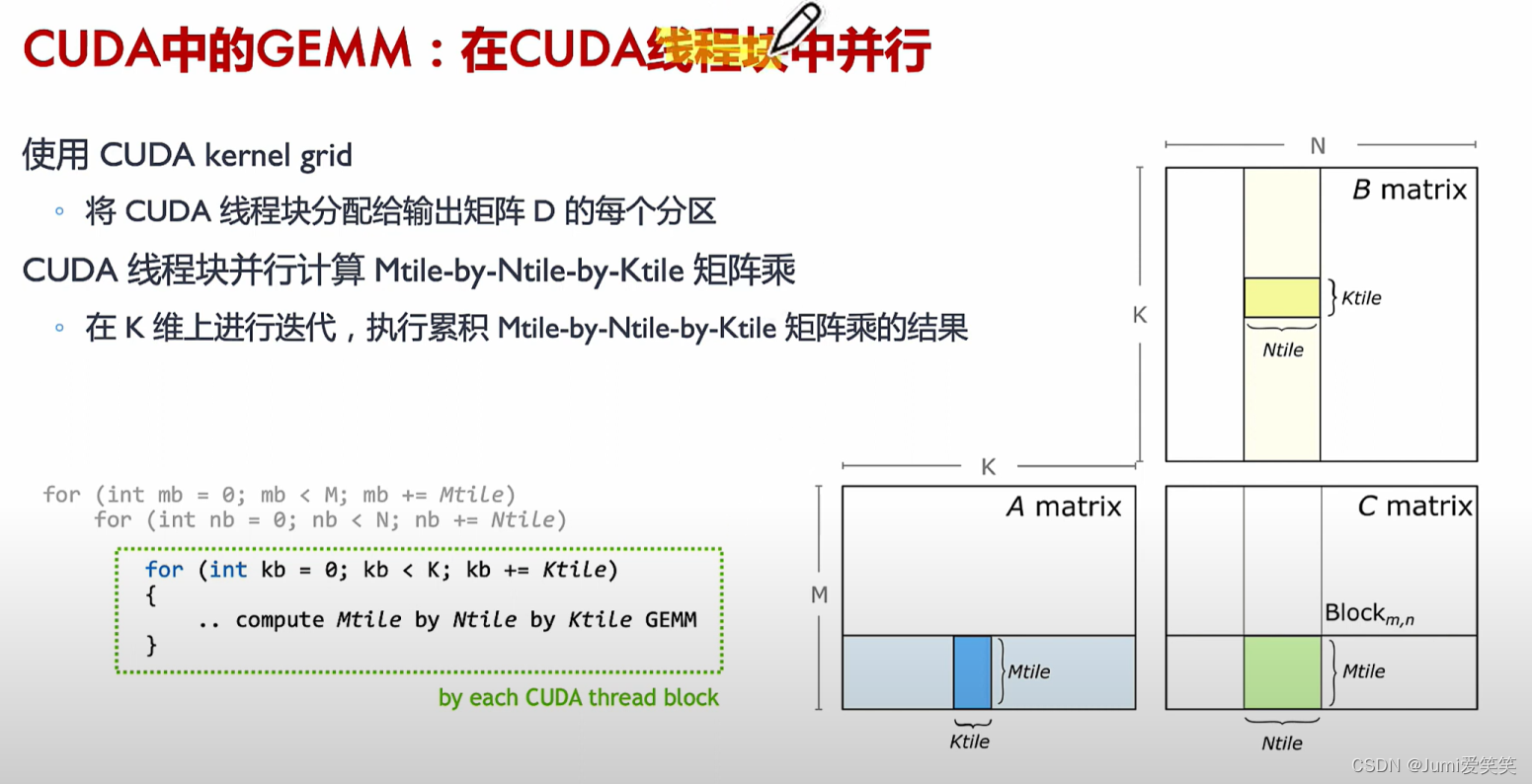
通用矩阵乘CUDA实现_Block级
结合在CUDA中,首先将通用矩阵乘中的每个fragment分配给每个block;
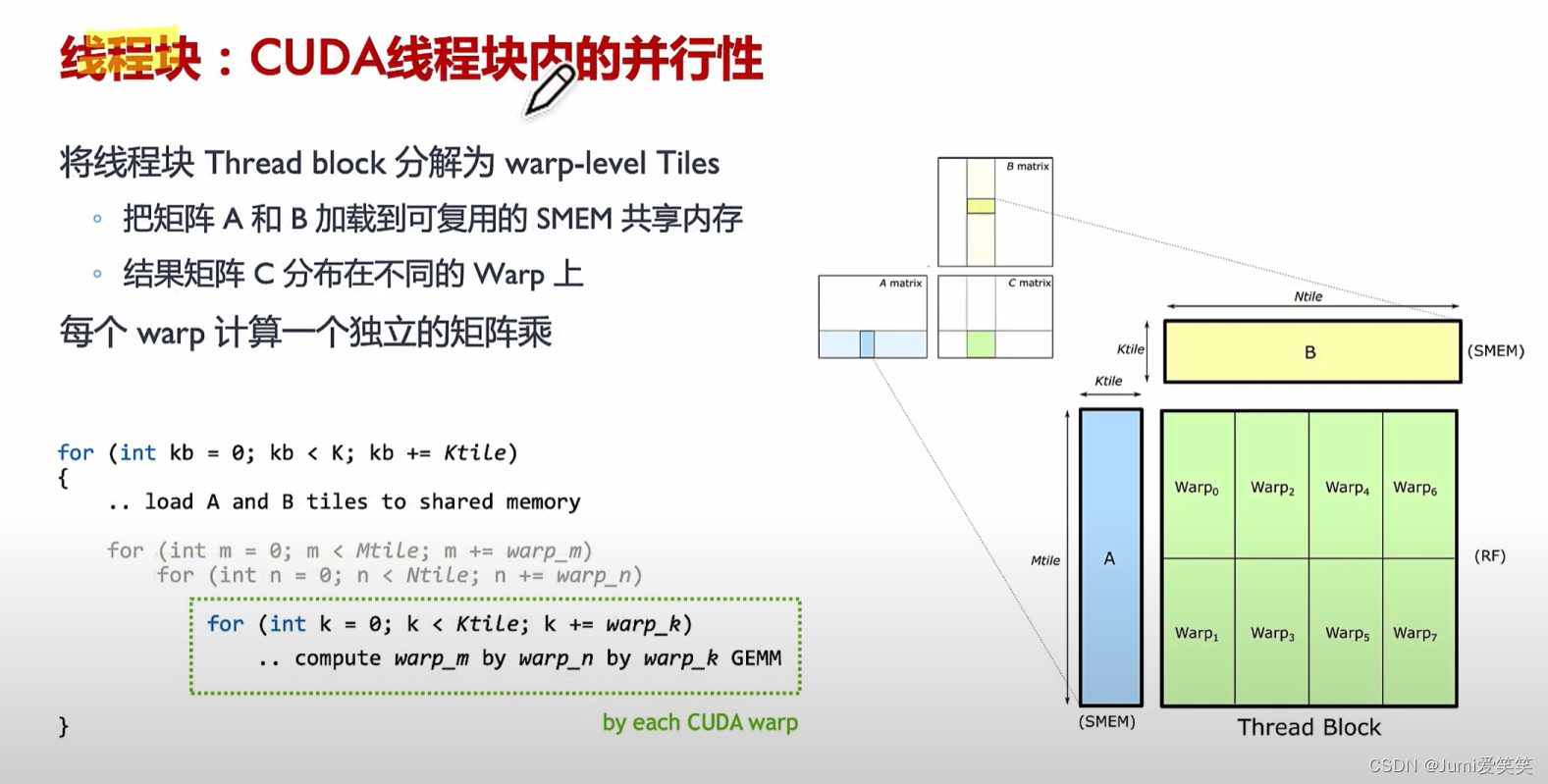
通用矩阵乘CUDA实现_Warp级
在Block中,每个Warp执行一个独立的矩阵乘;
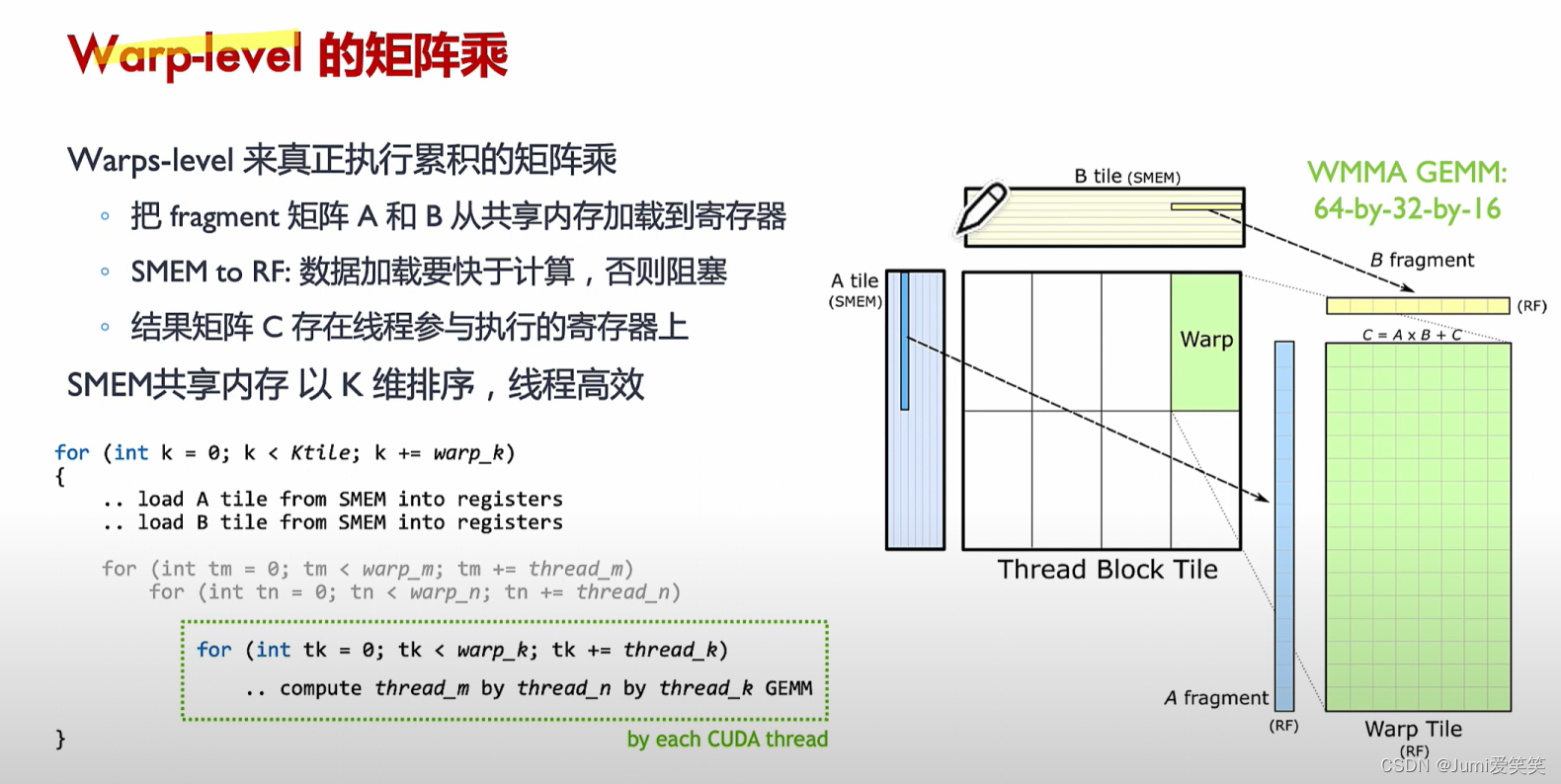
通用矩阵乘CUDA实现_Warp-level
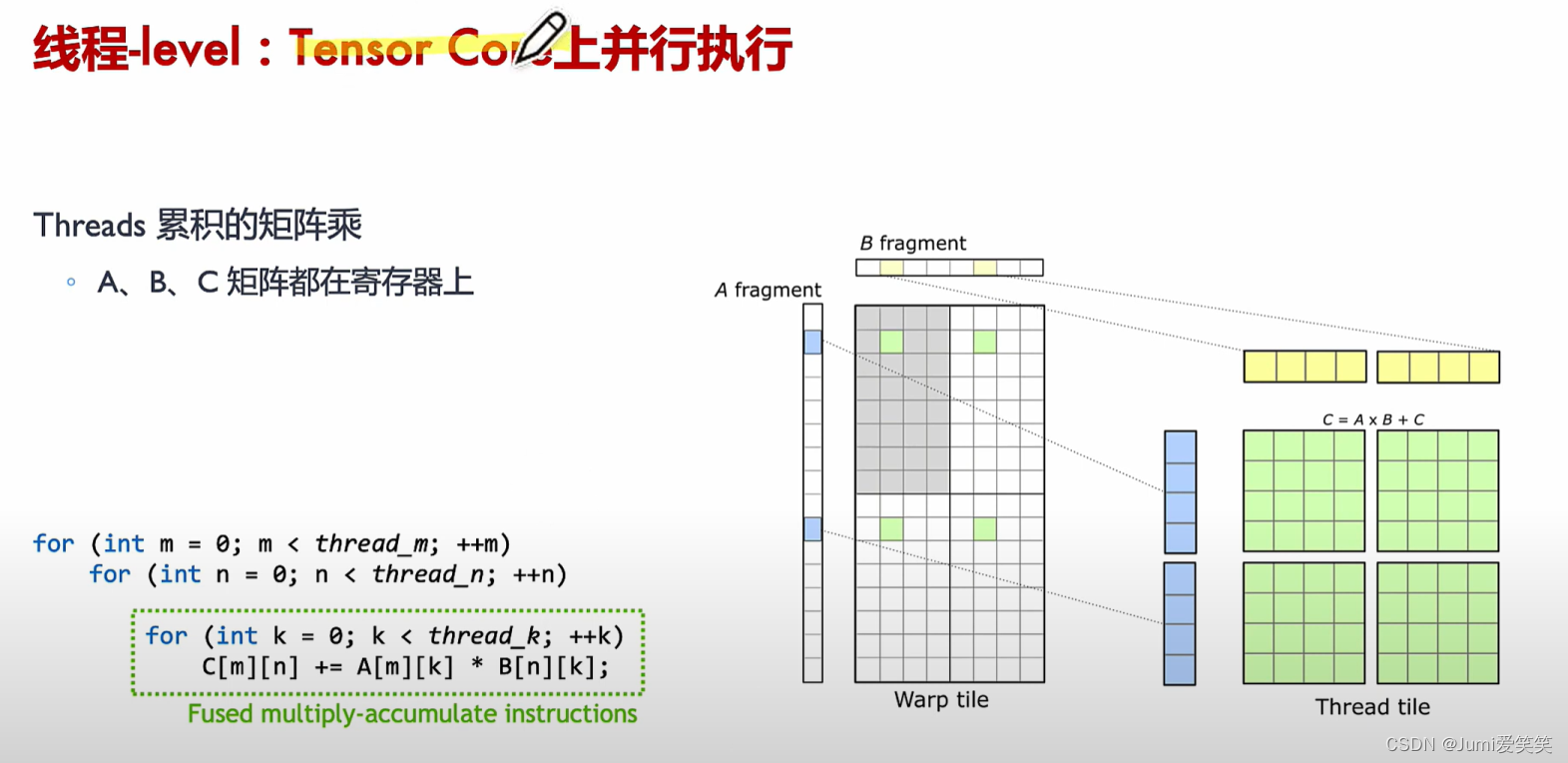
通用矩阵乘CUDA实现_Thread-level
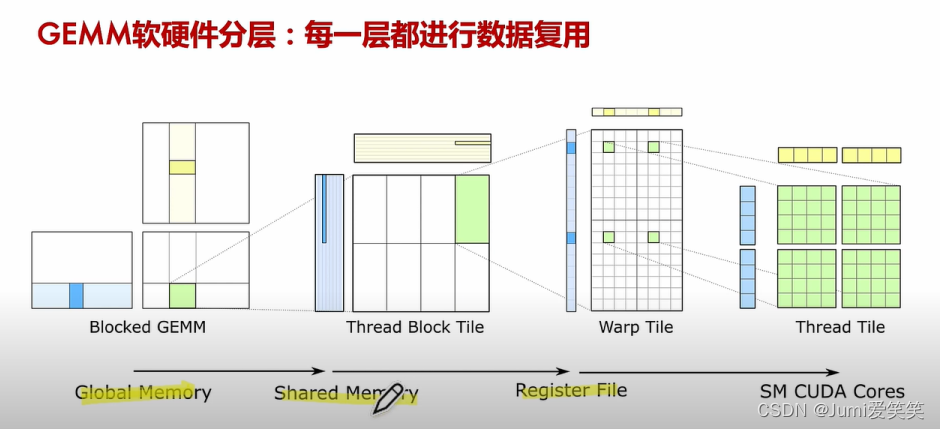
通用矩阵乘CUDA实现_软硬件分层
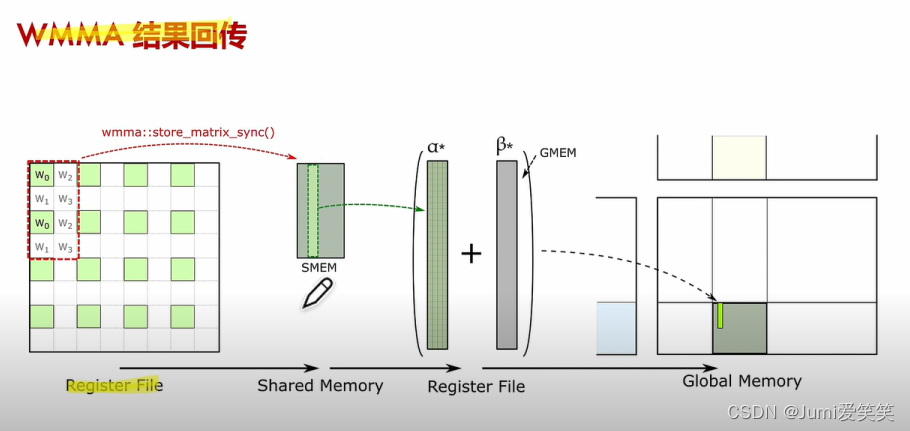
通用矩阵乘CUDA实现_结果回传
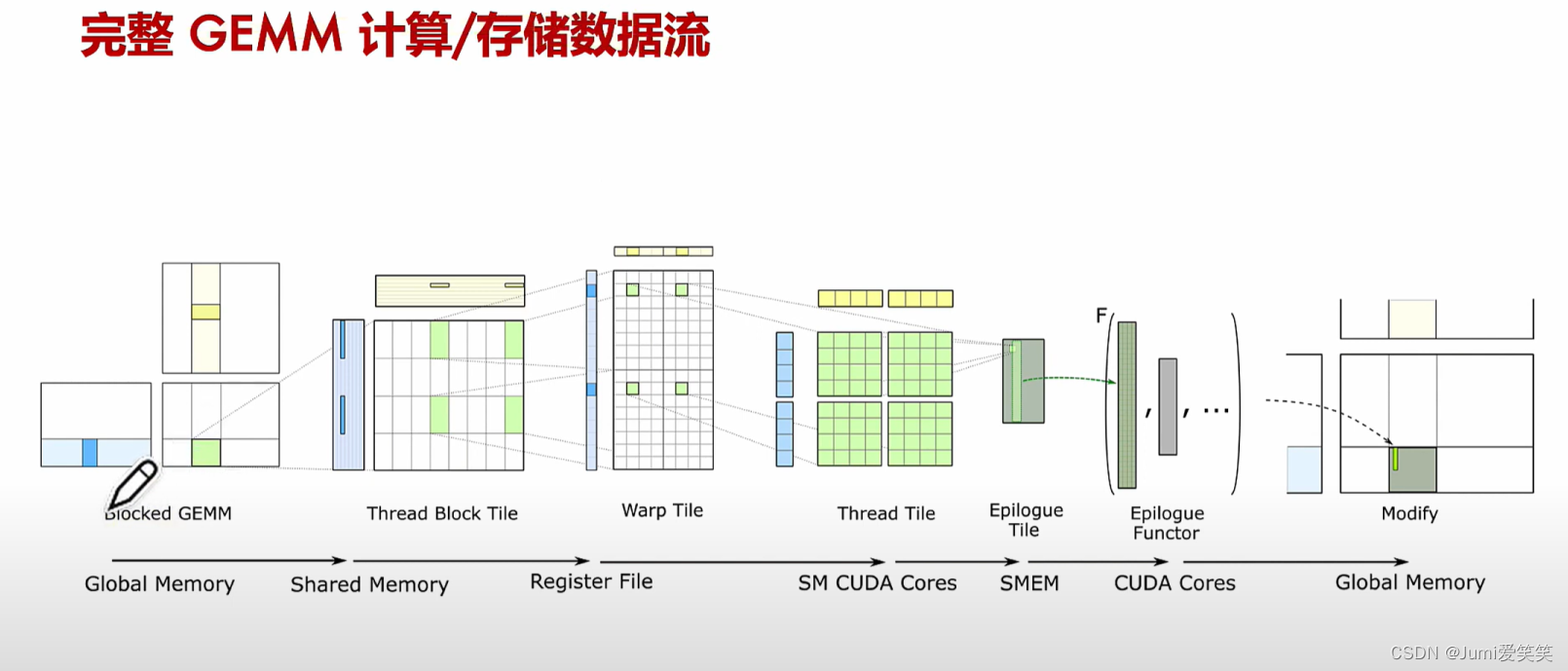
通用矩阵乘CUDA实现_总体结构
Tensor Core 具体实现GEMM(General Matrix Multiply)的过程如下:
Blocked GEMM:
矩阵首先从全局内存加载到共享内存。这个过程涉及将大矩阵划分为较小的子块(称为Tile)。这些Tile被分配到CUDA线程块中。
Thread Block Tile:
每个线程块负责处理一个矩阵块。这些线程块会将数据从全局内存读取到共享内存中。在这个阶段,数据准备就绪,等待进一步处理。
Warp Tile:
共享内存中的数据被分配给不同的warp。warp是CUDA编程模型中的基本执行单元,通常由32个线程组成。在这个阶段,每个warp从共享内存中读取相应的矩阵块数据。
Thread Tile:
每个线程在warp中处理一个更小的矩阵子块。这些子块的大小通常是与Tensor Core硬件匹配的16x16或更小的尺寸。这里,矩阵片段被加载到寄存器文件中。
SM CUDA Cores:
Tensor Core执行矩阵乘法累加操作(WMMA::mma_sync)。在这个过程中,片段(fragments)被利用,硬件执行高效的矩阵乘法操作,将结果存储到累加器中。
Epilogue Tile:
完成矩阵乘法操作后,结果被存储回共享内存。在这个阶段,Epilogue Functor可以应用到结果上,这可能包括非线性激活函数或其他后处理操作。
Modify:
最后的结果从共享内存写回全局内存。在写回之前,可能会有一些修改操作,确保数据正确性和完整性.
数据流详细分析
> Global Memory to Shared Memory:大块数据从全局内存
Shared Memory to Register File:共享内存中的数据被分配到寄存器文件(Register File),这一步骤主要由warp和线程来执行,以确保每个线程都有其需要的数据。
Register File to SM CUDA Cores:寄存器文件中的数据被Tensor Cores使用,执行高效的矩阵乘法操作。WMMA API(例如wmma::mma_sync)在这个阶段起作用。
Shared Memory for Epilogue Tile:执行完矩阵乘法后,结果被存储在共享内存中,等待进一步处理或直接写回全局内存。
Global Memory Write-back:最终结果从共享内存写回到全局内存,完成整个GEMM操作。
上图的GEMM过程演示了在Tensor Core上的经过,下面用代码进行说明:
🌰:
// 详细注释说明以便理解
#include <mma.h>
#include <cuda_runtime.h>
#include <iostream>
using namespace nvcuda;
#define M 1024
#define N 1024
#define K 1024
__global__ void matrixMulKernel(const half* __restrict__ A, const half* __restrict__ B, float* __restrict__ C, int M, int N, int K) {
// Declare shared memory to hold the tiles of A and B
// 声明存储矩阵A和B片段的共享内存区域
__shared__ half shared_A[16][16];
__shared__ half shared_B[16][16];
// Declare the fragments
// 使用 WMMA 声明矩阵片段,a_frag 和 b_frag 分别用于存储矩阵 A 和 B 的片段,c_frag 用于累加结果。
wmma::fragment<wmma::matrix_a, 16, 16, 16, half, wmma::col_major> a_frag;
wmma::fragment<wmma::matrix_b, 16, 16, 16, half, wmma::row_major> b_frag;
wmma::fragment<wmma::accumulator, 16, 16, 16, float> c_frag;
// 计算 warp 的位置
int warpM = (blockIdx.y * blockDim.y + threadIdx.y) / 16;
int warpN = (blockIdx.x * blockDim.x + threadIdx.x) / 16;
wmma::fill_fragment(c_frag, 0.0f);
for (int i = 0; i < K; i += 16) {
int aRow = warpM * 16 + threadIdx.y % 16;
int aCol = i + threadIdx.x % 16;
int bRow = i + threadIdx.y % 16;
int bCol = warpN * 16 + threadIdx.x % 16;
// 计算共享内存中的行和列索引,并将矩阵 A 和 B 的数据加载到共享内存中
if (aRow < M && aCol < K) {
shared_A[threadIdx.y % 16][threadIdx.x % 16] = A[aRow * K + aCol];
} else {
shared_A[threadIdx.y % 16][threadIdx.x % 16] = 0.0;
}
if (bRow < K && bCol < N) {
shared_B[threadIdx.y % 16][threadIdx.x % 16] = B[bRow * N + bCol];
} else {
shared_B[threadIdx.y % 16][threadIdx.x % 16] = 0.0;
}
__syncthreads();
wmma::load_matrix_sync(a_frag, shared_A[0], 16);
wmma::load_matrix_sync(b_frag, shared_B[0], 16);
wmma::mma_sync(c_frag, a_frag, b_frag, c_frag);
__syncthreads();
}
// 计算输出矩阵 C 的行和列索引并将累加结果从 c_frag 存储到全局内存中的矩阵C
int cRow = warpM * 16 + threadIdx.y % 16;
int cCol = warpN * 16 + threadIdx.x % 16;
if (cRow < M && cCol < N) {
wmma::store_matrix_sync(C + cRow * N + cCol, c_frag, N, wmma::mem_row_major);
}
}
void matrixMultiply(const half* A, const half* B, float* C, int M, int N, int K) {
dim3 threadsPerBlock(16, 16);
dim3 blocksPerGrid((N + 15) / 16, (M + 15) / 16);
matrixMulKernel<<<blocksPerGrid, threadsPerBlock>>>(A, B, C, M, N, K);
cudaDeviceSynchronize();
}
int main() {
// Allocate and initialize host matrices
half *h_A, *h_B;
float *h_C;
cudaMallocHost(&h_A, M * K * sizeof(half));
cudaMallocHost(&h_B, K * N * sizeof(half));
cudaMallocHost(&h_C, M * N * sizeof(float));
for (int i = 0; i < M * K; i++) h_A[i] = __float2half(1.0f);
for (int i = 0; i < K * N; i++) h_B[i] = __float2half(1.0f);
for (int i = 0; i < M * N; i++) h_C[i] = 0.0f;
// Allocate and initialize device matrices
half *d_A, *d_B;
float *d_C;
cudaMalloc(&d_A, M * K * sizeof(half));
cudaMalloc(&d_B, K * N * sizeof(half));
cudaMalloc(&d_C, M * N * sizeof(float));
cudaMemcpy(d_A, h_A, M * K * sizeof(half), cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, K * N * sizeof(half), cudaMemcpyHostToDevice);
// Perform matrix multiplication on the device
matrixMultiply(d_A, d_B, d_C, M, N, K);
// Copy the result back to host
cudaMemcpy(h_C, d_C, M * N * sizeof(float), cudaMemcpyDeviceToHost);
// Print the result
std::cout << "Result: " << std::endl;
for (int i = 0; i < 10; i++) {
for (int j = 0; j < 10; j++) {
std::cout << h_C[i * N + j] << " ";
}
std::cout << std::endl;
}
// Cleanup
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
cudaFreeHost(h_A);
cudaFreeHost(h_B);
cudaFreeHost(h_C);
return 0;
}从上述程序中可以看出,在使用wmma::mma_sync函数 WMMA (Warp Matrix Multiply Accumulate)) 时,需要将矩阵划分为适合Tensor Cores处理的块。具体来说,矩阵需要划分为16x16的子矩阵,以便与Tensor Cores的工作方式匹配。如果矩阵的尺寸不是16的倍数,则需要填充或对矩阵进行分块处理,以使其适应Tensor Cores的操作。
在调用wmma::mma_sync时,确保以下几点:
- 矩阵的维度应为16的倍数。
- 使用wmma::fragment来定义输入和输出的片段。
- 通过wmma::load_matrix_sync将矩阵数据加载到片段中。
- 使用wmma::mma_sync执行矩阵乘法。
- 通过wmma::store_matrix_sync将结果存储回全局内存。
而在平时的CUDA编程中,使用cuBLAS库或深度学习框架等即可自动使用Tensor Core进行加速。
THANKS FOR REFERENCE:
Tensor Core 基本原理 CUDA Core Tensor Core RT CoreAI 工作负载 线程束(Warp) CNN GEMM 混合精度训练