从矩阵转置看共享内存(CUDA的使用:Bank Conflict与Memory Coalesce)
矩阵转置是一种基础的矩阵操作, 即将二维矩阵的行列进行反转,本文主要围绕行主序的二维单精度矩阵的转置考虑相关的优化。
矩阵的转置就是将矩阵中的元素按照主对角线进行交换。具体来说,对于一个矩阵 $A$,其转置矩阵 $A^T$ 的定义是: $A^T[i][j] = A[j][i]$ 。这意味着,矩阵 $A$ 的第 $i$ 行第 $j$ 列的元素在转置矩阵 $A^T$ 中变成了第 $j$ 行第 $i$ 列的元素。换句话说,矩阵中的元素是相对于主对角线对称交换的。
🌰:
Original matrix:
1 2 3 4
5 6 7 8
9 10 11 12
13 14 15 16
Transposed matrix:
1 5 9 13
2 6 10 14
3 7 11 15
4 8 12 16矩阵转置的几种方法:
矩阵转置朴素实现: {#sector_1}
__global__ void mat_transpose_kernel_v0(const float* idata, float* odata, int M, int N) {
const int x = blockIdx.x * blockDim.x + threadIdx.x;
const int y = blockIdx.y * blockDim.y + threadIdx.y;
if (y < M && x < N) {
odata[x * M + y] = idata[y * N + x];
}
}
void mat_transpose_v0(const float* idata, float* odata, int M, int N) {
constexpr int BLOCK_SZ = 16;
dim3 block(BLOCK_SZ, BLOCK_SZ);
dim3 grid((N + BLOCK_SZ - 1) / BLOCK_SZ, (M + BLOCK_SZ - 1) / BLOCK_SZ));
mat_transpose_kernel_v0<<<grid, block>>>(idata, odata, M, N);
}矩阵转置的朴素实现非常直观, 思路即使用二维的线程/线程块排布, 让每个线程负责一个矩阵元素的转置. 实现上, 只需要将矩阵的行列索引 x y 进行反转即可.
需要注意的是 grid 和 block 的中维度设置与多维数组中的表示是相反的, 即 grid.x 应该对应 N 维度, grid.y 应该对应 M 维度.
结合矩阵转置的逻辑以及 Nsight Compute 容易判断出, 矩阵转置本身是一个 memory-bound 的 kernel, 因为其核心是完成矩阵内存排布的转换, 这个过程基本不涉及计算, 因此对该 kernel 优化很重要的一点就是提高访存性能.
朴素实现直接操作矩阵所在的 GMEM, 直观看来, 矩阵转置不会涉及数据的重用, 直接操作 GMEM 本身没有问题, 但此时应该注意 GMEM 的访存特性, 其中很重要的即 GMEM 的访存合并, 即连续线程访问的 GMEM 中的数据地址是连续的, 可以将多个线程的内存访问合并为一个(或多个)内存访问, 从而减少访存次数, 提高带宽利用率. 在 Version 0 的 kernel 中, 容易看出读取时 idata[y * N + x] 是访存合并的, 因为连续线程对应的 x 是连续的, 即访问矩阵同一行连续的列; 但是写入时 odata[x * M + y] 并不是访存合并的, 因为转置后连续线程写入的是同一列连续的行, 但由于内存布局是行主序的, 因此此时每个线程访问的地址实际上并不连续, 地址差 N, 因此对 GMEM 访存性能有很大影响.
利用共享内存合并访存: {#sector_2}
template <int BLOCK_SZ>
__global__ void mat_transpose_kernel_v1(const float* idata, float* odata, int M, int N) {
const int bx = blockIdx.x, by = blockIdx.y;
const int tx = threadIdx.x, ty = threadIdx.y;
__shared__ float sdata[BLOCK_SZ][BLOCK_SZ];
int x = bx * BLOCK_SZ + tx;
int y = by * BLOCK_SZ + ty;
if (y < M && x < N) {
sdata[ty][tx] = idata[y * N + x];
}
__syncthreads();
x = by * BLOCK_SZ + tx;
y = bx * BLOCK_SZ + ty;
if (y < N && x < M) {
odata[y * M + x] = sdata[tx][ty];
}
}
void mat_transpose_v1(const float* idata, float* odata, int M, int N) {
constexpr int BLOCK_SZ = 16;
dim3 block(BLOCK_SZ, BLOCK_SZ);
dim3 grid(Ceil(N, BLOCK_SZ), Ceil(M, BLOCK_SZ));
mat_transpose_kernel_v1<BLOCK_SZ><<<grid, block>>>(idata, odata, M, N);
}利用共享内存进行合并访存时,实现了读出和写入时的访存合并 (Memory Coalesce).但此时在共享内存中会出现由于读入和写出时数据操作不一致导致的 odata[y * M + x] = sdata[tx][ty]; 出现每两行出现 Bank Conflict 冲突,从而造成了 16路的内存冲突;
利用共享内存进行矩阵转置
Version 1 的核心思想可以使用上图进行表示, 中间的 "tile" 即可理解为存在 SMEM 的数据分片.
在读取矩阵阶段, 操作与 Version 0 一致, 区别在于将数据直接写入 SMEM 中, 对应上图橙色部分. 接着通过设置 x = by * BLOCK_SZ + tx; y = bx * BLOCK_SZ + ty; 两条语句进行了索引的重计算, 进行了线程块索引 bx 和 by 交换, 对应上图右上角的数据分片转置后成为了左下角的数据分片. 由于此时 tx 和 ty 并没有交换, 因此按照 odata[y * M + x] 写入 GMEM 时, 访存是合并的, 但需要读取 SMEM 时 tx 与 ty 进行交换, 实现数据分片内的转置, 对应上图绿色部分.
利用 padding 解决 bank conflict: {#sector_3}
template <int BLOCK_SZ>
__global__ void mat_transpose_kernel_v2(const float* idata, float* odata, int M, int N) {
const int bx = blockIdx.x, by = blockIdx.y;
const int tx = threadIdx.x, ty = threadIdx.y;
__shared__ float sdata[BLOCK_SZ][BLOCK_SZ+1]; // padding
int x = bx * BLOCK_SZ + tx;
int y = by * BLOCK_SZ + ty;
if (y < M && x < N) {
sdata[ty][tx] = idata[y * N + x];
}
__syncthreads();
x = by * BLOCK_SZ + tx;
y = bx * BLOCK_SZ + ty;
if (y < N && x < M) {
odata[y * M + x] = sdata[tx][ty];
}
}
void mat_transpose_v2(const float* idata, float* odata, int M, int N) {
constexpr int BLOCK_SZ = 16;
dim3 block(BLOCK_SZ, BLOCK_SZ);
dim3 grid(Ceil(N, BLOCK_SZ), Ceil(M, BLOCK_SZ));
mat_transpose_kernel_v2<BLOCK_SZ><<<grid, block>>>(idata, odata, M, N);
}
sdata[ty][tx]

sdata[tx][ty]
Version 2 的代码相比于 Version 1 仅在 SMEM 内存分配时进行了变动, 将大小改为了 sdata[BLOCK_SZ][BLOCK_SZ+1], 即列维度上加入了 1 元素大小的 padding.
此时, 对于读取 SMEM 的 sdata[tx][ty], threadIdx 差 1 的线程访问的数据差 BLOCK_SZ+1, 即 17, 由于 17 与 32 互质, 因此不会有 bank conflict. 值得一提的是, 对于写入 SMEM 的 sdata[ty][tx], 由于有 1 个 padding, warp 中 lane 31 与 lane 0 访问的元素恰好差 31+1=32 个元素, 会有 1 个 bank conflict.
增加每个线程的处理元素个数: {#sector_4}
template <int BLOCK_SZ, int NUM_PER_THREAD>
__global__ void mat_transpose_kernel_v3(const float* idata, float* odata, int M, int N) {
const int bx = blockIdx.x, by = blockIdx.y;
const int tx = threadIdx.x, ty = threadIdx.y;
__shared__ float sdata[BLOCK_SZ][BLOCK_SZ+1];
int x = bx * BLOCK_SZ + tx;
int y = by * BLOCK_SZ + ty;
constexpr int ROW_STRIDE = BLOCK_SZ / NUM_PER_THREAD;
if (x < N) {
#pragma unroll
for (int y_off = 0; y_off < BLOCK_SZ; y_off += ROW_STRIDE) {
if (y + y_off < M) {
sdata[ty + y_off][tx] = idata[(y + y_off) * N + x];
}
}
}
__syncthreads();
x = by * BLOCK_SZ + tx;
y = bx * BLOCK_SZ + ty;
if (x < M) {
for (int y_off = 0; y_off < BLOCK_SZ; y_off += ROW_STRIDE) {
if (y + y_off < N) {
odata[(y + y_off) * M + x] = sdata[tx][ty + y_off];
}
}
}
}
void mat_transpose_v3(const float* idata, float* odata, int M, int N) {
constexpr int BLOCK_SZ = 32;
constexpr int NUM_PER_THREAD = 4;
dim3 block(BLOCK_SZ, BLOCK_SZ/NUM_PER_THREAD);
dim3 grid(Ceil(N, BLOCK_SZ), Ceil(M, BLOCK_SZ));
mat_transpose_kernel_v3<BLOCK_SZ, NUM_PER_THREAD><<<grid, block>>>(idata, odata, M, N);
}对于增加线程计算元素个数,使用了更少的线程来进行转置从而提高计算访存比(广义上的计算,因为矩阵转置实质上不进行计算,仅仅是访存及位置的互换),实现了在列维度上的线程数量的减少。在这时,sdata[ty + y_off][tx] 的 bank 实现了无冲突 (这时其实由于共享内存的bank是32路,其实也没有冲突)。

sdata[ty + y_off][tx]
而在sdata[tx][ty + y_off] 中,由于交错排列,也避免了内存冲突。

sdata[tx][ty + y_off]
Version 3 相比于 Version 2, 增加了每个线程处理的元素个数, 即由先前的每个线程处理 1 个元素的转置, 变为处理 NUM_PER_THREAD 个元素的转置. 该实现主要是参考了 英伟达的技术博客.
在实现上, 同样保持原本 256 线程的线程块大小, 设置每个线程处理 4 个元素, 则每个线程块数据分片的大小调整为 32×32, 而线程块的线程采取 8×32 的二维排布, 因此需要在行维度上需要迭代 4 次完成转置.
考虑 Version 3 相比于 Version 2 的优势, 主要是在保持线程块中线程数量不变的情况下, 处理的线程块数据分片大小变大, 这样会减少线程网格中启动的线程块数量, 而增大了每个线程的计算强度; 此外, 由于 BLOCK_SZ 变为 32, Version 2 中写入 SMEM 的 1 个 bank conflict 也可以被避免.
这让笔者想到了 Reduce 算子中也会考虑增加每个线程处理的元素来提高性能, 笔者主观的感觉是对于这种计算强度比较低的 kernel, 增加线程处理的元素个数即计算强度, 一定程度上能增大 GPU 中计算与访存的掩盖, 并配合循环展开提高指令级并行; 此外, 由于线程块数量的减少, 能在相对少的 wave 中完成计算, 减少 GPU 的线程块调度上可能也会带来性能的收益.
向量化存取: {#sector_5}
向量化存取的关键在于
#define FETCH_CFLOAT4(p) (reinterpret_cast<const float4*>(&(p))[0])
#define FETCH_FLOAT4(p) (reinterpret_cast<float4*>(&(p))[0])这两句代码实现了使用FETCH_FLOAT4和FETCH_CFLOAT4一次性读取和存储4个浮点数。将指针p强制转换为const float4和float4类型,并获取第一个float4类型的值。float4是一个包含4个浮点数的CUDA内置向量类型,这种转换可以一次性处理4个浮点数,从而提高内存访问的效率。
#define FETCH_CFLOAT4(p) (reinterpret_cast<const float4*>(&(p))[0])
#define FETCH_FLOAT4(p) (reinterpret_cast<float4*>(&(p))[0])
template <int BLOCK_SZ>
__global__ void mat_transpose_kernel_v3_5(const float* idata, float* odata, int M, int N) {
const int bx = blockIdx.x, by = blockIdx.y;
const int tx = threadIdx.x, ty = threadIdx.y;
__shared__ float sdata[BLOCK_SZ][BLOCK_SZ];
int x = bx * BLOCK_SZ + tx * 4;
int y = by * BLOCK_SZ + ty;
if (x < N && y < M) {
FETCH_FLOAT4(sdata[ty][tx * 4]) = FETCH_CFLOAT4(idata[y * N + x]);
}
__syncthreads();
x = by * BLOCK_SZ + tx * 4;
y = bx * BLOCK_SZ + ty;
float tmp[4];
if (x < M && y < N) {
#pragma unroll
for (int i = 0; i < 4; ++i) {
tmp[i] = sdata[tx * 4 + i][ty];
}
FETCH_FLOAT4(odata[y * M + x]) = FETCH_FLOAT4(tmp);
}
}
void mat_transpose_v3_5(const float* idata, float* odata, int M, int N) {
constexpr int BLOCK_SZ = 32;
dim3 block(BLOCK_SZ / 4, BLOCK_SZ);
dim3 grid(Ceil(N, BLOCK_SZ), Ceil(M, BLOCK_SZ));
mat_transpose_kernel_v3_5<BLOCK_SZ><<<grid, block>>>(idata, odata, M, N);
}此时利用向量化访存的效率是比单纯利用共享内存高的,但是由于无法避免bank conflict,运行时间还是有较大延迟。
矩阵转置综合应用: {#chapter_2}
Float数据类型转置: {#float}
/* Copyright (c) 1993-2015, NVIDIA CORPORATION. All rights reserved.
*
* Redistribution and use in source and binary forms, with or without
* modification, are permitted provided that the following conditions
* are met:
* * Redistributions of source code must retain the above copyright
* notice, this list of conditions and the following disclaimer.
* * Redistributions in binary form must reproduce the above copyright
* notice, this list of conditions and the following disclaimer in the
* documentation and/or other materials provided with the distribution.
* * Neither the name of NVIDIA CORPORATION nor the names of its
* contributors may be used to endorse or promote products derived
* from this software without specific prior written permission.
*
* THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS ``AS IS'' AND ANY
* EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
* IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
* PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR
* CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL,
* EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
* PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR
* PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY
* OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
* (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
* OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
*/
#include <stdio.h>
#include <assert.h>
// 方便的CUDA运行时API结果检查函数
// 可以包装任何运行时API调用。在发布版本中无操作。
inline
cudaError_t checkCuda(cudaError_t result)
{
#if defined(DEBUG) || defined(_DEBUG)
if (result != cudaSuccess) {
fprintf(stderr, "CUDA Runtime Error: %s\n", cudaGetErrorString(result));
assert(result == cudaSuccess);
}
#endif
return result;
}
const int TILE_DIM = 32;
const int BLOCK_ROWS = 8;
// 内核重复执行次数
const int NUM_REPS = 5;
// 检查错误并打印GB/s
void postprocess(const float *ref, const float *res, int n, float ms)
{
bool passed = true;
for (int i = 0; i < n; i++)
if (res[i] != ref[i]) {
printf("%d %f %f\n", i, res[i], ref[i]);
printf("%25s\n", "*** FAILED ***");
passed = false;
break;
}
if (passed)
printf("%20.2f\n", 2 * n * sizeof(float) * 1e-6 * NUM_REPS / ms );
}
// 简单复制内核
// 作为基准案例,表示最佳有效带宽。
__global__ void copy(float *odata, const float *idata)
{
int x = blockIdx.x * TILE_DIM + threadIdx.x;
int y = blockIdx.y * TILE_DIM + threadIdx.y;
int width = gridDim.x * TILE_DIM;
for (int j = 0; j < TILE_DIM; j+= BLOCK_ROWS)
odata[(y+j)*width + x] = idata[(y+j)*width + x];
}
// 使用共享内存的复制内核
// 也是基准案例,展示了使用共享内存的效果。
__global__ void copySharedMem(float *odata, const float *idata)
{
__shared__ float tile[TILE_DIM * TILE_DIM];
int x = blockIdx.x * TILE_DIM + threadIdx.x;
int y = blockIdx.y * TILE_DIM + threadIdx.y;
int width = gridDim.x * TILE_DIM;
for (int j = 0; j < TILE_DIM; j += BLOCK_ROWS)
tile[(threadIdx.y+j)*TILE_DIM + threadIdx.x] = idata[(y+j)*width + x];
__syncthreads();
for (int j = 0; j < TILE_DIM; j += BLOCK_ROWS)
odata[(y+j)*width + x] = tile[(threadIdx.y+j)*TILE_DIM + threadIdx.x];
}
// 简单转置
// 最简单的转置;不使用共享内存。
// 全局内存读取是合并的,但写入不是。
__global__ void transposeNaive(float *odata, const float *idata)
{
int x = blockIdx.x * TILE_DIM + threadIdx.x;
int y = blockIdx.y * TILE_DIM + threadIdx.y;
int width = gridDim.x * TILE_DIM;
for (int j = 0; j < TILE_DIM; j+= BLOCK_ROWS)
odata[x*width + (y+j)] = idata[(y+j)*width + x];
}
// 合并转置
// 使用共享内存来实现读取和写入的合并
// tile宽度==bank数量会导致共享内存bank冲突。
__global__ void transposeCoalesced(float *odata, const float *idata)
{
__shared__ float tile[TILE_DIM][TILE_DIM];
int x = blockIdx.x * TILE_DIM + threadIdx.x;
int y = blockIdx.y * TILE_DIM + threadIdx.y;
int width = gridDim.x * TILE_DIM;
for (int j = 0; j < TILE_DIM; j += BLOCK_ROWS)
tile[threadIdx.y+j][threadIdx.x] = idata[(y+j)*width + x];
__syncthreads();
x = blockIdx.y * TILE_DIM + threadIdx.x; // 转置块偏移
y = blockIdx.x * TILE_DIM + threadIdx.y;
for (int j = 0; j < TILE_DIM; j += BLOCK_ROWS)
odata[(y+j)*width + x] = tile[threadIdx.x][threadIdx.y + j];
}
// 无bank冲突转置
// 与transposeCoalesced相同,只是第一个tile维度填充
// 以避免共享内存bank冲突。
__global__ void transposeNoBankConflicts(float *odata, const float *idata)
{
__shared__ float tile[TILE_DIM][TILE_DIM+1];
int x = blockIdx.x * TILE_DIM + threadIdx.x;
int y = blockIdx.y * TILE_DIM + threadIdx.y;
int width = gridDim.x * TILE_DIM;
for (int j = 0; j < TILE_DIM; j += BLOCK_ROWS)
tile[threadIdx.y+j][threadIdx.x] = idata[(y+j)*width + x];
__syncthreads();
x = blockIdx.y * TILE_DIM + threadIdx.x; // 转置块偏移
y = blockIdx.x * TILE_DIM + threadIdx.y;
for (int j = 0; j < TILE_DIM; j += BLOCK_ROWS)
odata[(y+j)*width + x] = tile[threadIdx.x][threadIdx.y + j];
}
int main(int argc, char **argv)
{
const int nx = 2048;
const int ny = 2048;
const int mem_size = nx*ny*sizeof(float);
dim3 dimGrid(nx/TILE_DIM, ny/TILE_DIM, 1);
dim3 dimBlock(TILE_DIM, BLOCK_ROWS, 1);
int devId = 0;
if (argc > 1) devId = atoi(argv[1]);
cudaDeviceProp prop;
checkCuda( cudaGetDeviceProperties(&prop, devId));
printf("\nDevice : %s\n", prop.name);
printf("Matrix size: %d %d, Block size: %d %d, Tile size: %d %d\n",
nx, ny, TILE_DIM, BLOCK_ROWS, TILE_DIM, TILE_DIM);
printf("dimGrid: %d %d %d. dimBlock: %d %d %d\n",
dimGrid.x, dimGrid.y, dimGrid.z, dimBlock.x, dimBlock.y, dimBlock.z);
checkCuda( cudaSetDevice(devId) );
float *h_idata = (float*)malloc(mem_size);
float *h_cdata = (float*)malloc(mem_size);
float *h_tdata = (float*)malloc(mem_size);
float *gold = (float*)malloc(mem_size);
float *d_idata, *d_cdata, *d_tdata;
checkCuda( cudaMalloc(&d_idata, mem_size) );
checkCuda( cudaMalloc(&d_cdata, mem_size) );
checkCuda( cudaMalloc(&d_tdata, mem_size) );
// 检查参数并计算执行配置
if (nx % TILE_DIM || ny % TILE_DIM) {
printf("nx 和 ny 必须是 TILE_DIM 的倍数\n");
goto error_exit;
}
if (TILE_DIM % BLOCK_ROWS) {
printf("TILE_DIM 必须是 BLOCK_ROWS 的倍数\n");
goto error_exit;
}
// 主机
for (int j = 0; j < ny; j++)
for (int i = 0; i < nx; i++)
h_idata[j*nx + i] = j*nx + i;
// 用于错误检查的正确结果
for (int j = 0; j < ny; j++)
for (int i = 0; i < nx; i++)
gold[j*nx + i] = h_idata[i*nx + j];
// 设备
checkCuda( cudaMemcpy(d_idata, h_idata, mem_size, cudaMemcpyHostToDevice) );
// 用于计时的事件
cudaEvent_t startEvent, stopEvent;
checkCuda( cudaEventCreate(&startEvent) );
checkCuda( cudaEventCreate(&stopEvent) );
float ms;
// ------------
// 内核计时
// ------------
printf("%25s%25s\n", "Routine", "Bandwidth (GB/s)");
// ----
// 复制
// ----
printf("%25s", "copy");
checkCuda( cudaMemset(d_cdata, 0, mem_size) );
// 预热
copy<<<dimGrid, dimBlock>>>(d_cdata, d_idata);
checkCuda( cudaEventRecord(startEvent, 0) );
for (int i = 0; i < NUM_REPS; i++)
copy<<<dimGrid, dimBlock>>>(d_cdata, d_idata);
checkCuda( cudaEventRecord(stopEvent, 0) );
checkCuda( cudaEventSynchronize(stopEvent) );
checkCuda( cudaEventElapsedTime(&ms, startEvent, stopEvent) );
checkCuda( cudaMemcpy(h_cdata, d_cdata, mem_size, cudaMemcpyDeviceToHost) );
postprocess(h_idata, h_cdata, nx*ny, ms);
// -------------
// 使用共享内存的复制
// -------------
printf("%25s", "shared memory copy");
checkCuda( cudaMemset(d_cdata, 0, mem_size) );
// 预热
copySharedMem<<<dimGrid, dimBlock>>>(d_cdata, d_idata);
checkCuda( cudaEventRecord(startEvent, 0) );
for (int i = 0; i < NUM_REPS; i++)
copySharedMem<<<dimGrid, dimBlock>>>(d_cdata, d_idata);
checkCuda( cudaEventRecord(stopEvent, 0) );
checkCuda( cudaEventSynchronize(stopEvent) );
checkCuda( cudaEventElapsedTime(&ms, startEvent, stopEvent) );
checkCuda( cudaMemcpy(h_cdata, d_cdata, mem_size, cudaMemcpyDeviceToHost) );
postprocess(h_idata, h_cdata, nx * ny, ms);
// --------------
// 简单转置
// --------------
printf("%25s", "naive transpose");
checkCuda( cudaMemset(d_tdata, 0, mem_size) );
// 预热
transposeNaive<<<dimGrid, dimBlock>>>(d_tdata, d_idata);
checkCuda( cudaEventRecord(startEvent, 0) );
for (int i = 0; i < NUM_REPS; i++)
transposeNaive<<<dimGrid, dimBlock>>>(d_tdata, d_idata);
checkCuda( cudaEventRecord(stopEvent, 0) );
checkCuda( cudaEventSynchronize(stopEvent) );
checkCuda( cudaEventElapsedTime(&ms, startEvent, stopEvent) );
checkCuda( cudaMemcpy(h_tdata, d_tdata, mem_size, cudaMemcpyDeviceToHost) );
postprocess(gold, h_tdata, nx * ny, ms);
// ------------------
// 合并转置
// ------------------
printf("%25s", "coalesced transpose");
checkCuda( cudaMemset(d_tdata, 0, mem_size) );
// 预热
transposeCoalesced<<<dimGrid, dimBlock>>>(d_tdata, d_idata);
checkCuda( cudaEventRecord(startEvent, 0) );
for (int i = 0; i < NUM_REPS; i++)
transposeCoalesced<<<dimGrid, dimBlock>>>(d_tdata, d_idata);
checkCuda( cudaEventRecord(stopEvent, 0) );
checkCuda( cudaEventSynchronize(stopEvent) );
checkCuda( cudaEventElapsedTime(&ms, startEvent, stopEvent) );
checkCuda( cudaMemcpy(h_tdata, d_tdata, mem_size, cudaMemcpyDeviceToHost) );
postprocess(gold, h_tdata, nx * ny, ms);
// ------------------------
// 无bank冲突转置
// ------------------------
printf("%25s", "conflict-free transpose");
checkCuda( cudaMemset(d_tdata, 0, mem_size) );
// 预热
transposeNoBankConflicts<<<dimGrid, dimBlock>>>(d_tdata, d_idata);
checkCuda( cudaEventRecord(startEvent, 0) );
for (int i = 0; i < NUM_REPS; i++)
transposeNoBankConflicts<<<dimGrid, dimBlock>>>(d_tdata, d_idata);
checkCuda( cudaEventRecord(stopEvent, 0) );
checkCuda( cudaEventSynchronize(stopEvent) );
checkCuda( cudaEventElapsedTime(&ms, startEvent, stopEvent) );
checkCuda( cudaMemcpy(h_tdata, d_tdata, mem_size, cudaMemcpyDeviceToHost) );
postprocess(gold, h_tdata, nx * ny, ms);
error_exit:
// 清理
checkCuda( cudaEventDestroy(startEvent) );
checkCuda( cudaEventDestroy(stopEvent) );
checkCuda( cudaFree(d_tdata) );
checkCuda( cudaFree(d_cdata) );
checkCuda( cudaFree(d_idata) );
free(h_idata);
free(h_tdata);
free(h_cdata);
free(gold);
}上述程序参考了NIVIDA官方社区示例程序并加以补充完善,基本实现了完整的CUDA程序的编写过程,且程序中每个线程都跨列执行4个数据的执行。程序中首先定义checkCuda标准错误函数以及结果检验和带宽计算postprocess函数,接着定义copy和copySharedMem两个基准程序以作为不使用/使用Shared Memory下的最大带宽。
Tip
在转置的实现中,transposeNaive函数利用Global Memory实现了基本的转置操作,但由于转置操作特性,导致其只在读取矩阵时实现了合并访存,在写入时并没有实现。在transposeCoalesced函数中,利用Shared Memory实现了对于全局内存读取以及写入的访存合并,但在共享内存的读取时由于转置操作特性,导致了bank conflict的出现。最后在transposeNoBankConflicts程序中,通过引入padding,解决了内存冲突的问题。
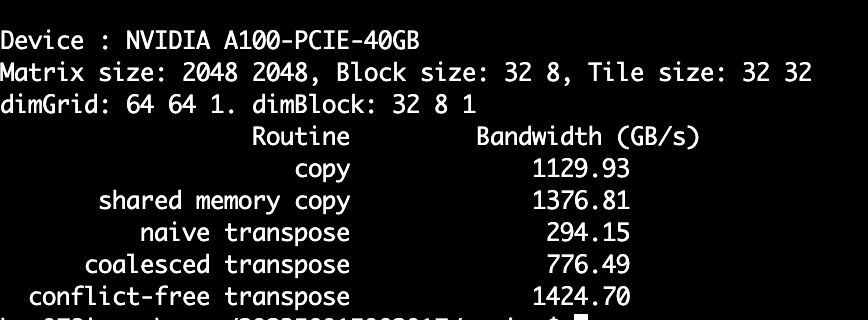
运行结果
Double数据类型转置: {#double}
/* Copyright (c) 1993-2015, NVIDIA CORPORATION. All rights reserved.
*
* Redistribution and use in source and binary forms, with or without
* modification, are permitted provided that the following conditions
* are met:
* * Redistributions of source code must retain the above copyright
* notice, this list of conditions and the following disclaimer.
* * Redistributions in binary form must reproduce the above copyright
* notice, this list of conditions and the following disclaimer in the
* documentation and/or other materials provided with the distribution.
* * Neither the name of NVIDIA CORPORATION nor the names of its
* contributors may be used to endorse or promote products derived
* from this software without specific prior written permission.
*
* THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS ``AS IS'' AND ANY
* EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
* IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
* PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR
* CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL,
* EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
* PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR
* PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY
* OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
* (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
* OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
*/
#include <stdio.h>
#include <assert.h>
// 方便的CUDA运行时API结果检查函数
// 可以包装任何运行时API调用。在发布版本中无操作。
inline
cudaError_t checkCuda(cudaError_t result)
{
#if defined(DEBUG) || defined(_DEBUG)
if (result != cudaSuccess) {
fprintf(stderr, "CUDA Runtime Error: %s\n", cudaGetErrorString(result));
assert(result == cudaSuccess);
}
#endif
return result;
}
// 定义常量
const int TILE_DIM = 32; // tile维度
const int BLOCK_ROWS = 8; // 块行数
const int NUM_REPS = 5; // 内核重复执行次数
// 检查错误并打印GB/s
void postprocess(const double *ref, const double *res, int n, double ms)
{
bool passed = true;
for (int i = 0; i < n; i++)
if (res[i] != ref[i]) {
printf("%d %f %f\n", i, res[i], ref[i]);
printf("%25s\n", "*** FAILED ***");
passed = false;
break;
}
if (passed)
printf("%20.2f\n", 2 * n * sizeof(double) * 1e-6 * NUM_REPS / ms );
}
// 简单复制内核
// 作为基准案例,表示最佳有效带宽。
__global__ void copy(double *odata, const double *idata)
{
int x = blockIdx.x * TILE_DIM + threadIdx.x;
int y = blockIdx.y * TILE_DIM + threadIdx.y;
int width = gridDim.x * TILE_DIM;
for (int j = 0; j < TILE_DIM; j+= BLOCK_ROWS)
odata[(y+j)*width + x] = idata[(y+j)*width + x];
}
// 使用共享内存的复制内核
// 也是基准案例,展示了使用共享内存的效果。
__global__ void copySharedMem(double *odata, const double *idata)
{
__shared__ double tile[TILE_DIM * TILE_DIM];
int x = blockIdx.x * TILE_DIM + threadIdx.x;
int y = blockIdx.y * TILE_DIM + threadIdx.y;
int width = gridDim.x * TILE_DIM;
for (int j = 0; j < TILE_DIM; j += BLOCK_ROWS)
tile[(threadIdx.y+j)*TILE_DIM + threadIdx.x] = idata[(y+j)*width + x];
__syncthreads();
for (int j = 0; j < TILE_DIM; j += BLOCK_ROWS)
odata[(y+j)*width + x] = tile[(threadIdx.y+j)*TILE_DIM + threadIdx.x];
}
// 简单转置内核
// 最简单的转置;不使用共享内存。
// 全局内存读取是合并的,但写入不是。
__global__ void transposeNaive(double *odata, const double *idata)
{
int x = blockIdx.x * TILE_DIM + threadIdx.x;
int y = blockIdx.y * TILE_DIM + threadIdx.y;
int width = gridDim.x * TILE_DIM;
for (int j = 0; j < TILE_DIM; j+= BLOCK_ROWS)
odata[x*width + (y+j)] = idata[(y+j)*width + x];
}
// 合并转置内核
// 使用共享内存来实现读取和写入的合并
// tile宽度==ban k数量会导致共享内存bank冲突。
__global__ void transposeCoalesced(double *odata, const double *idata)
{
__shared__ double tile[TILE_DIM][TILE_DIM];
int x = blockIdx.x * TILE_DIM + threadIdx.x;
int y = blockIdx.y * TILE_DIM + threadIdx.y;
int width = gridDim.x * TILE_DIM;
for (int j = 0; j < TILE_DIM; j += BLOCK_ROWS)
tile[threadIdx.y+j][threadIdx.x] = idata[(y+j)*width + x];
__syncthreads();
x = blockIdx.y * TILE_DIM + threadIdx.x; // 转置块偏移
y = blockIdx.x * TILE_DIM + threadIdx.y;
for (int j = 0; j < TILE_DIM; j += BLOCK_ROWS)
odata[(y+j)*width + x] = tile[threadIdx.x][threadIdx.y + j];
}
// 无bank冲突转置内核
// 与transposeCoalesced相同,只是第一个ti le维度填充
// 以避免共享内存bank冲突。
__global__ void transposeNoBankConflicts(double *odata, const double *idata)
{
__shared__ double tile[TILE_DIM][TILE_DIM+1];
int x = blockIdx.x * TILE_DIM + threadIdx.x;
int y = blockIdx.y * TILE_DIM + threadIdx.y;
int width = gridDim.x * TILE_DIM;
// 卷帘方式存取
for (int j = 0; j < TILE_DIM; j += BLOCK_ROWS)
tile[threadIdx.y+j][threadIdx.x] = idata[(y+j)*width + x];
__syncthreads();
x = blockIdx.y * TILE_DIM + threadIdx.x; // 转置块偏移
y = blockIdx.x * TILE_DIM + threadIdx.y;
for (int j = 0; j < TILE_DIM; j += BLOCK_ROWS)
odata[(y+j)*width + x] = tile[threadIdx.x][threadIdx.y + j];
}
int main(int argc, char **argv)
{
const int nx = 2048; // 矩阵的x维度
const int ny = 2048; // 矩阵的y维度
const int mem_size = nx*ny*sizeof(double); // 矩阵所需的内存大小
dim3 dimGrid(nx/TILE_DIM, ny/TILE_DIM, 1); // 网格维度
dim3 dimBlock(TILE_DIM, BLOCK_ROWS, 1); // 块维度
int devId = 0;
if (argc > 1) devId = atoi(argv[1]);
cudaDeviceProp prop;
checkCuda( cudaGetDeviceProperties(&prop, devId));
printf("\nDevice : %s\n", prop.name);
printf("Matrix size: %d %d, Block size: %d %d, Tile size: %d %d\n",
nx, ny, TILE_DIM, BLOCK_ROWS, TILE_DIM, TILE_DIM);
printf("dimGrid: %d %d %d. dimBlock: %d %d %d\n",
dimGrid.x, dimGrid.y, dimGrid.z, dimBlock.x, dimBlock.y, dimBlock.z);
checkCuda( cudaSetDevice(devId) );
double *h_idata = (double*)malloc(mem_size); // 主机输入数据
double *h_cdata = (double*)malloc(mem_size); // 主机复制数据
double *h_tdata = (double*)malloc(mem_size); // 主机转置数据
double *gold = (double*)malloc(mem_size); // 主机正确结果
double *d_idata, *d_cdata, *d_tdata;
checkCuda( cudaMalloc(&d_idata, mem_size) ); // 设备输入数据
checkCuda( cudaMalloc(&d_cdata, mem_size) ); // 设备复制数据
checkCuda( cudaMalloc(&d_tdata, mem_size) ); // 设备转置数据
// 检查参数并计算执行配置
if (nx % TILE_DIM || ny % TILE_DIM) {
printf("nx 和 ny 必须是 TILE_DIM 的倍数\n");
goto error_exit;
}
if (TILE_DIM % BLOCK_ROWS) {
printf("TILE_DIM 必须是 BLOCK_ROWS 的倍数\n");
goto error_exit;
}
// 初始化主机输入数据
for (int j = 0; j < ny; j++)
for (int i = 0; i < nx; i++)
h_idata[j*nx + i] = j*nx + i;
// 初始化主机正确结果
for (int j = 0; j < ny; j++)
for (int i = 0; i < nx; i++)
gold[j*nx + i] = h_idata[i*nx + j];
// 将输入数据从主机复制到设备
checkCuda( cudaMemcpy(d_idata, h_idata, mem_size, cudaMemcpyHostToDevice) );
// 用于计时的事件
cudaEvent_t startEvent, stopEvent;
checkCuda( cudaEventCreate(&startEvent) );
checkCuda( cudaEventCreate(&stopEvent) );
float ms;
// ------------
// 内核计时
// ------------
printf("%25s%25s\n", "Routine", "Bandwidth (GB/s)");
// ----
// 复制
// ----
printf("%25s", "copy");
checkCuda( cudaMemset(d_cdata, 0, mem_size) ); // 清空设备复制数据
// 预热
copy<<<dimGrid, dimBlock>>>(d_cdata, d_idata);
checkCuda( cudaEventRecord(startEvent, 0) );
for (int i = 0; i < NUM_REPS; i++)
copy<<<dimGrid, dimBlock>>>(d_cdata, d_idata);
checkCuda( cudaEventRecord(stopEvent, 0) );
checkCuda( cudaEventSynchronize(stopEvent) );
checkCuda( cudaEventElapsedTime(&ms, startEvent, stopEvent) );
checkCuda( cudaMemcpy(h_cdata, d_cdata, mem_size, cudaMemcpyDeviceToHost) );
postprocess(h_idata, h_cdata, nx*ny, ms);
// -------------
// 使用共享内存的复制
// -------------
printf("%25s", "shared memory copy");
checkCuda( cudaMemset(d_cdata, 0, mem_size) ); // 清空设备复制数据
// 预热
copySharedMem<<<dimGrid, dimBlock>>>(d_cdata, d_idata);
checkCuda( cudaEventRecord(startEvent, 0) );
for (int i = 0; i < NUM_REPS; i++)
copySharedMem<<<dimGrid, dimBlock>>>(d_cdata, d_idata);
checkCuda( cudaEventRecord(stopEvent, 0) );
checkCuda( cudaEventSynchronize(stopEvent) );
checkCuda( cudaEventElapsedTime(&ms, startEvent, stopEvent) );
checkCuda( cudaMemcpy(h_cdata, d_cdata, mem_size, cudaMemcpyDeviceToHost) );
postprocess(h_idata, h_cdata, nx * ny, ms);
// --------------
// 简单转置
// --------------
printf("%25s", "naive transpose");
checkCuda( cudaMemset(d_tdata, 0, mem_size) ); // 清空设备转置数据
// 预热
transposeNaive<<<dimGrid, dimBlock>>>(d_tdata, d_idata);
checkCuda( cudaEventRecord(startEvent, 0) );
for (int i = 0; i < NUM_REPS; i++)
transposeNaive<<<dimGrid, dimBlock>>>(d_tdata, d_idata);
checkCuda( cudaEventRecord(stopEvent, 0) );
checkCuda( cudaEventSynchronize(stopEvent) );
checkCuda( cudaEventElapsedTime(&ms, startEvent, stopEvent) );
checkCuda( cudaMemcpy(h_tdata, d_tdata, mem_size, cudaMemcpyDeviceToHost) );
postprocess(gold, h_tdata, nx * ny, ms);
// ------------------
// 合并转置
// ------------------
printf("%25s", "coalesced transpose");
checkCuda( cudaMemset(d_tdata, 0, mem_size) ); // 清空设备转置数据
// 预热
transposeCoalesced<<<dimGrid, dimBlock>>>(d_tdata, d_idata);
checkCuda( cudaEventRecord(startEvent, 0) );
for (int i = 0; i < NUM_REPS; i++)
transposeCoalesced<<<dimGrid, dimBlock>>>(d_tdata, d_idata);
checkCuda( cudaEventRecord(stopEvent, 0) );
checkCuda( cudaEventSynchronize(stopEvent) );
checkCuda( cudaEventElapsedTime(&ms, startEvent, stopEvent) );
checkCuda( cudaMemcpy(h_tdata, d_tdata, mem_size, cudaMemcpyDeviceToHost) );
postprocess(gold, h_tdata, nx * ny, ms);
// ------------------------
// 无bank冲突转置
// ------------------------
printf("%25s", "conflict-free transpose");
checkCuda( cudaMemset(d_tdata, 0, mem_size) ); // 清空设备转置数据
// 预热
transposeNoBankConflicts<<<dimGrid, dimBlock>>>(d_tdata, d_idata);
checkCuda( cudaEventRecord(startEvent, 0) );
for (int i = 0; i < NUM_REPS; i++)
transposeNoBankConflicts<<<dimGrid, dimBlock>>>(d_tdata, d_idata);
checkCuda( cudaEventRecord(stopEvent, 0) );
checkCuda( cudaEventSynchronize(stopEvent) );
checkCuda( cudaEventElapsedTime(&ms, startEvent, stopEvent) );
checkCuda( cudaMemcpy(h_tdata, d_tdata, mem_size, cudaMemcpyDeviceToHost) );
postprocess(gold, h_tdata, nx * ny, ms);
error_exit:
// 清理
checkCuda( cudaEventDestroy(startEvent) );
checkCuda( cudaEventDestroy(stopEvent) );
checkCuda( cudaFree(d_tdata) );
checkCuda( cudaFree(d_cdata) );
checkCuda( cudaFree(d_idata) );
free(h_idata);
free(h_tdata);
free(h_cdata);
free(gold);
}
运行结果
由于共享内存的bank为32位即4字节,所以double和float的优化机制会有些许不同。
对于写入Shared Memory的操作:
for (int j = 0; j < 16; j += 16)
tile[threadIdx.y+j][threadIdx.x] = idata[(y+j)*width + x];
__syncthreads();
Double类型'伪合并访存'
可以注意到,在每个warp中,每个线程负责两个double数据。
另外,对于下述代码情况:
for (int j = 0; j < 16; j += 16)
odata[(y+j)*width + x] = tile[threadIdx.x][threadIdx.y + j];
Double类型'伪非合并访存'
在如上图中,每个bank中都会发生16路bank冲突,所以改进增加padding:

Double类型'伪非合并访存'
Caution
在这里会有疑问,为什么同一个warp中的前16个线程和后16个线程不会发生bank conflict呢?事实上,要辩证深入本质看bank conflict的定义,当Shared Memory的32个bank发生非同时访问(即部分bank有一个access,另外部分不只有一个access)时,由于多个访问同时访问一个bank,导致产生顺序访问,拖慢了访存节奏,此时就会产生bank conflict。而在这里由于每次访问都会将32个bank同时访问,也就是占满了Shared Memory的带宽,当然也就不会发生冲突。
REFERENCE(感谢引用):